moxie: incremental declarative UI in Rust
moxie is a small incremental computing runtime focused on efficient declarative UI, written in Rust. moxie itself aims to be platform-agnostic, offering tools to higher-level crates that work on specific platforms. Most applications using moxie will do so through bindings between the runtime and a concrete UI system like the web or a consumer desktop platform.
The general goal of moxie is to empower Rustaceans to write UI code "generically with respect to time," describing the state of the UI right now for any value of now. This can be seen in some code samples below, and I'll discuss how this works further down.
This post has been forming for a while, and I find myself finally getting to it thanks to Raph's thought-provoking post on reactive UI. I'll discuss a bit of how I view moxie's approach to declarative UI in Rust and how the project fits into the mental model Raph explores in his post.
A few months before writing this I gave a talk at RustConf 2019 which covers many similar concepts and subjects, and a version of it with Q&A at the SF meetup. If you're reading this you may also find them interesting.
Bindingsahoy
moxie-dom demoahoy
The most mature user of it today is moxie-dom, a crate for defining web applications in pure Rust using WebAssembly.1
The web is pretty cool. Here is a counter built with moxie-dom, embedded into an iframe. You can click the button and watch the count climb! Wow! 2
Here's the code for that:
moxie_dom::boot(document().body().unwrap(), || { let count = state!(|| 0); mox! {<> <div>{% "hello world from moxie! ({})", &count }</div> <button type="button" on={move |_: event::Click| count.update(|c| Some(c + 1))}> "increment" </button> </>}; for t in &["first", "second", "third"] { mox! { <div>{% "{}", t }</div> }; } });
In this example, the state! variable on the second line and the mox! macro with quasi-XML syntax
are both provided by the core moxie crate and can be shared between arbitrary UI "backends."
Each time the button is clicked, the closure in boot runs in entirety but if you open your
browser's devtools on the iframe, you should see that only the necessary DOM nodes are seeing
updates:
In addition to moxie-dom, rebo has been working on an interesting experiment to reuse a portion
of moxie's core logic to add hooks to the Seed web framework.
moxie-nativeahoy
My earlier experiments with moxie were aimed at desktop applications without any web dependency, and this is something I know many in the Rust community are eager to see come together. In that vein, Tiffany Bennett has a very new project called moxie-native which is exploring the use of moxie and WebRender to create desktop UI. These Windows and Linux screenshots:
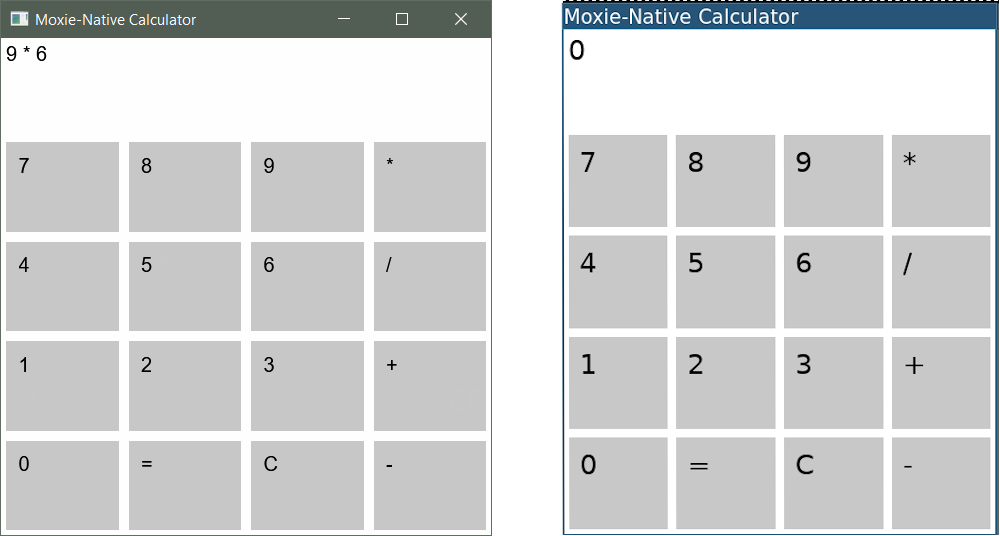
are produced from this code:
use moxie_native::prelude::*; // eliding definitions for CalcState, Message, etc... #[topo::nested] #[illicit::from_env(state: &Key<CalcState>)] fn calc_function(message: Message) -> Node<Button> { let state = state.clone(); let on_click = move |_event: &ClickEvent| state.update(|state| Some(state.process(message))); let text = match message { Message::Cls => "C".to_owned(), Message::Equ => "=".to_owned(), Message::Digit(digit) => digit.to_string(), Message::Op(Op::Add) => "+".to_owned(), Message::Op(Op::Sub) => "-".to_owned(), Message::Op(Op::Mul) => "*".to_owned(), Message::Op(Op::Div) => "/".to_owned(), }; mox!( <button style={BUTTON_STYLE} on={on_click}> <span>{text}</span> </button> ) } #[topo::nested] #[illicit::from_env(state: &Key<CalcState>)] fn calculator() -> Node<App> { mox! { <app> <window title="Moxie-Native Calculator"> <view style={ROW_STYLE}> <span>{% "{}", state.display()}</span> </view> <view style={ROW_STYLE}> <calc_function _=(Message::Digit(7)) /> <calc_function _=(Message::Digit(8)) /> <calc_function _=(Message::Digit(9)) /> <calc_function _=(Message::Op(Op::Mul)) /> </view> <view style={ROW_STYLE}> <calc_function _=(Message::Digit(4)) /> <calc_function _=(Message::Digit(5)) /> <calc_function _=(Message::Digit(6)) /> <calc_function _=(Message::Op(Op::Div)) /> </view> <view style={ROW_STYLE}> <calc_function _=(Message::Digit(1)) /> <calc_function _=(Message::Digit(2)) /> <calc_function _=(Message::Digit(3)) /> <calc_function _=(Message::Op(Op::Add)) /> </view> <view style={ROW_STYLE}> <calc_function _=(Message::Digit(0)) /> <calc_function _=(Message::Equ) /> <calc_function _=(Message::Cls) /> <calc_function _=(Message::Op(Op::Sub)) /> </view> </window> </app> } } fn main() { let runtime = moxie_native::Runtime::new(|| { let state = state!(|| CalcState::new()); let with_state = illicit::child_env!(Key<CalcState> => state); with_state.enter(|| calculator!()) }); runtime.start(); }
As you can see, it's still early days but (for me at least) it's extremely exciting! It's also
worth noting that it's possible to write all of this functionality without the mox macro, even if
it's not yet pleasant -- I have some thoughts for that too. Full disclosure: Tiffany is also using a
small fork of the macro that allows for statically-checked DOM mount-points, we should be able to
reconverge soon but in the meantime the macro code in these snippets isn't exactly identical.
And more!ahoy
I am eager to see moxie powering apps on top of many underlying frameworks in the future, including those written using moxie as the main incremental tool (for the extremely adventurous only!). If you're interested in using moxie to write bindings to the framework of your choice, please come join the chat! Because the core crates aren't that stable yet I think the chat channel is best but in the future I expect we'll have guides for writing bindings & integrations.
Mental Modelahoy
After the initial setup of any interactive UI, further changes are primarily driven by some kind of event. Once that event occurs, the program is responsible for computing what must change in the state of the application, deciding how the application's interface should be changed as a result, and then performing that update accordingly. Along the way it's typical to request future notifications of hardware inputs, timers, network events, or results from internal asynchronous tasks.
These events are usually handled in a loop, receiving information from the outside world and eventually generating changes in the presented interface. In this way, interactive applications resemble (meta-) control loops, constantly attempting to reconcile the external state of the interface with the "set value" defined by the application's logic.
moxie views the "control loop" code in UI applications as defining relations maintained over time:
+-------------+
events ----> |
| program |---> outputs
initial ----> |
inputs +-------------+
"Declarative" UIahoy
Our goal is to allow one to "declare" these relations directly in the program source. When we declare the shape of our UI in code, we are writing a program which will run repeatedly, each time computing a minimal update with minimal side effects while ensuring that the output matches the snapshot captured by the declaration.3
To make snapshots efficient, moxie recognizes that "declarative UI" must be what Adapton calls "incremental computation":
A program P is incremental if repeating P with a changed input is faster than from-scratch recomputation.
This means making decisions about how to structure our declarative applications in such a way as to reuse as much work as we can. Ideally we can do this while preserving other desired properties. We'd like to have generally portable semantics for our declarative runtime, so that Rustaceans can use it on a wide variety of targets and platforms. Expressing the computation incrementally should not undo the benefits of having a single declaration for all instances of the application -- it must still be pleasant enough to write.
Most existing UI systems have a way of dividing the output space of the application into nested hierarchies, each one containing 0 or more of its own sub-divisions. These subdivisions form a tree, with the root of the tree owning the total output space, its children owning their own portion each of that, and so on.
Assuming you're familiar with Rust's ownership model, this is more or less how Rust encourages
viewing execution and dataflow within a thread. Everything descends from main(), receiving smaller
inputs at each lower stage of decomposing the program into smaller function calls, accumulating
results on the way back up, informing later siblings and perhaps the final output.
In my opinion, regular function calls are the most "naturally Rustic" tools for modelling dynamic hierarchies. They have a very clear relationship to the ownership and reference models, are the default abstraction chosen when decomposing a solution to a problem, and underly Rust's uniform execution model. So moxie offers tools to declare outputs incrementally according to the shape of a callgraph.
Generic Incrementalityahoy
It needs to be efficient to capture a snapshot of the declared output, since it happens in a loop quite frequently. The primary tool that moxie offers for this is memoization of nested tree values which are stored by the runtime in-between calls of the program.
The simplest form of memoization is the once! macro, which never reinitializes its contents
after the first time:
let first = once!(|| Arc::new(String::new(include_str!("...")))); // ^ only runs once for this location in the tree // subsequent runs at this location will clone the Arc
Much of the time, expensive operations take a value as input which sometimes varies but is often stable. In those cases, we'd like to reuse the prior work whenever possible:
/// Reads the contents of the provided path as a string, returning a reference /// to it. The I/O is performed only when this is first called or when it has /// the contents of a different path cached. /// /// I don't recommend writing this function in your projects! So many reasons. #[topo::nested] fn intern_file_contents(path: &Path) -> Arc<String> { memo!(path, |p| Arc::new(std::fs::read_to_string(p).unwrap())) // ^ touches disk only when p changes }
Here, memo! takes the capture argument path, and runs the initialization closure whenever
path changes. If it's able to reuse a previous result, then it will Clone that and return it.
There are non-Clone options too, it's just the most straightforward for an example.
The storage is local to that callsite within that function, relative to the current location in the call tree. It holds values across snapshots, which allows our code to be written for "right now," regardless of prior executions. At the end of each snapshot, the runtime drops all values which were not referenced in the latest "revision." The initialization and destruction of each memoized value can therefore be used to model mount/unmount style lifecycle events -- a subject for another post.
Identifying Storage Locationsahoy
This memoization tool isn't very useful unless we can call it multiple times in a given snapshot, storing different values in different parts of the tree without interference between them.
In order to differentiate the usages of intern_file_contents! within two different callers, it is
annotated with #[topo::nested]. A unique topo::Id is constructed at the invocation of functions
annotated this way, which can be retrieved with topo::Id::current(). The Id is unique to the
parent Id which was active when the current function was called, the source location at which it
was created (so we can identify multiple calls within a parent function), and some runtime data we
call a "slot."
By default the slot used is the number of times that source location has already been called
during the parent Id. This provides a nice default behavior for looping over collections,
recursion, etc. The slot can always be overridden with a user-provided slot in cases where the
identity shouldn't be tied to execution order within the collection, for example in a list where the
contents are shuffled but individual list items remain intact.
With these combined, each Id refers to a stable location within our incremental program's call
tree. When we run our code multiple times, functions with the same "location" in the call tree will
receive Ids the same as their previous executions, allowing for a rendezvous with the output of
previous invocations.
Tying this together, each call to memo! during a given snapshot will receive a different Id
depending on tree location, and we use that as the index into our persistent cross-snapshot
storage. Future iterations of the snapshot process will be able to see that data provided their
execution takes the same path.
Driving Forwardahoy
The other main primitive in moxie is the state variable, which forms the interface between
the moxie runtime and underlying event-generating systems. State variables are memoized values
created with state!. They are mutated through the Key<T> returned from state!. Mutations
notify the embedding environment that the runtime must be scheduled for execution. Each time that
happens, another iteration of the control loop is entered and we snapshot the current interface
state.
Ask not what you must do for moxie,ahoy
This overall approach offers users of the core runtime many degrees of freedom in terms of how they express a UI system on top:
- moxie-dom incrementally mutates concrete DOM nodes during a declaration, binding them to a "scoped singleton" parent. The currently-mutating-node is then offered as the parent to child function calls.
- moxie-native components return memoized copy-on-write values which are incrementally evaluated in later stages of the pipeline.
- Previous experiments of mine have directly accumulated linear display lists for WebRender during the course of execution, and I expect that in the future I'll write some moxie bindings for Dear ImGui or another similarly "linearized snapshot" system.
There are still some admittedly serious restrictions that moxie imposes on users (like transforming
functions that create nodes in the tree into macros! or my quick'n'dirty use of hashing to create
topo::Ids turning out to be unsound), but I think we have paths to resolve all of them within a
few months.
Please email me, file an issue, or hop in the chat if you're trying things out and have questions or feedback. I'm eager to hear from you! It highlights places I can learn to improve my communication/process/design/etc, and helps me prioritize efforts! Plus, it's nice to hear about everyone's projects :D.
moxie and the Levien unified topologyahoy
So that's moxie qua moxie, or as well as I'm able to represent it right now.
If you haven't read Raph's excellent and thought-provoking post on reactive UI, I recommend either doing so first or skimming the rest of this post. Assuming you've read it, I'll be quoting liberally from it to add moxie-specific color to the ideas and to offer a few replies since I've built such a nice soapbox for myself here. True to Raph's inspiration, I'm following his walk through ideas since the satisfying narrative conclusion already happened up above.
there are two fundamental ways to represent a tree. First, as a data structure, ... Second, as a trace of excecution, ...
I think about this in terms of the shape of "tree snapshot" structure(s) captured and how. The spectrum of shapes of those data structures is quite broad, as Raph rightly notes. Garbage-collected heap references, identifers stored in ECS-style linear storage, vertex buffers, raw GPU command buffers, intermingled layers of some or all of these, etc.
The shapes of these structures determine which kinds of analyses a runtime or framework can perform to calculate e.g. layout, as well as the efficiency of capturing the snapshot of the application's visual state in the first place (what Raph calls app data -> widget tree and I tend to think of as the "capture" or "extraction" phase of application logic).
moxie's approach here is to use callsite-based IDs for identifying incremental storage, but to use initialization of that storage as a tool for memoizing mutations. You can call methods on a builder context, or manipulate tree nodes and connect them together. The goal of the core runtime is to allow for any strategy here, as long as it can fit in an initialization closure.4
Raph goes on to describe a model of producing these trees in pipelined stages, with nice diagrams:
There are a number of reasons to analyze the problem of UI as a pipeline of tree stages. Basically, the end-to-end transformation is so complicated it would be very difficult to express directly. So it's best to break it down into smaller chunks, stitched together in a pipeline.
...you want these tree-to-tree transformations to be incremental. In a UI, you're not dealing with one tree, but a time sequence of them, and most of the tree is not changing, just a small delta. One of the fundamental goals of a UI framework is to keep the deltas flowing down the pipeline small.
In my opinion this nicely sets the stage for the comparison between the architectures of contemporary "declarative UI pipelines" and those of today's optimizing compilers. Without going into too much depth, I'd argue that there is a similar trend at play with other tools undergoing batch -> interactive re-architectures or re-writes:
- incremental compilers built for IDE usage (Roslyn, rustc, the Skip research language was built
around a very cool self-hosting incremental toolchain, etc.)
- I quite like salsa as a generic tool in this space, and had tried a couple of times to implement moxie on top of it
- megabuild systems with strict DAG-based builds (e.g. Bazel)
- databases materializing synthetic views/tables/etc in response to writes to concrete tables
- streaming frameworks like differential dataflow
- etc
It seems to me that computing ecosystems prioritizing latency trend toward having "incremental computing engines" at their hearts.5 It's been identified by research projects like Adapton and others for a while now. I'm not terribly well-versed in the research in this niche, but it seems likely to be a fruitful place to learn.
This is especially true when the transformation is stateful, as it makes sense to attribute that state to a particular stage in the pipeline.
I agree, and this is one of the main ways in which the comparison between UI systems and compilers breaks down. Typical incremental compiler pipelines don't have to consume different types of events, just project updates.
Pulling from a tree basically means calling a function to access that part of the tree.
IIUC, another important implication of pull-based APIs in Rust is that you generally need concrete return types, intermediate iterator structs, and lifetimes/generics/etc require more effort.
One more thing to say about the interplay between sequence iterators and trees: it's certainly possible to express a tree as its flattening into a sequence of events, particularly "push" and "pop" (also commonly "start" and "end" in parser lingo) to represent the tree structure.
This is the structure that Dear ImGui uses, with ImGui::Begin(...) and ImGui::End() calls.
This is also the basic structure that I used in a demo I made in early 2019 with proto-moxie and
WebRender.
...a change to some node on the input can have nontrivial effects on other nodes in the output. This is the problem of "tracking dependencies" and probably accounts for most of the variation between frameworks.
I think one of the most general and useful strategies is diffing, ...you do a traversal (of some kind) of the output tree, and at each node you keep track of the focus, specifically which subtree of the input can possibly affect the result.
moxie does this, but at the level of individual let binding assignments, and the caller must
provide the "focus" (which moxie calls the "capture") value(s) that will be used to determine
whether to re-initialize the memoized value.
My hope here is that by keeping diffing, lifecycle, and updates local to specific variables, moxie can provide "incremental connective tissue" without requiring specific tree structures of its users.
Diffing is also available in a less clever, more brute-force form, by actually going over the trees and comparing their contents. This is, I think, quite the common pattern in JS reactive frameworks...
I think that most diffing strategies in JS-land compare virtual DOM trees against one another, rather than comparing directly with the DOM. I could be wrong. A good thing to look closely at if someone were to write more summary content!
I'm not going to spend a lot of words on other incremental strategies, as it's a huge topic. But besides diffing, the other major approach is explicit deltas, most commonly (but not always) expressed as mutations. Then, you annotate the tree with "listeners," which are called when the node receives a mutation...
Interestingly, moxie combines these two approaches. Memoized values could be said to be "diffed" by
checking the arguments against the existing storage. Updates are only visible to the runtime via
state variables which require calling update(...) or set(...) on them to cause a state
transition.
bookkeeping to identify a subtree of the output that can change, and causes recomputation of that. There's a choice of granularity there, and a pattern I see a lot (cf Recompose in Jetpack Compose) is to address a node in the output tree and schedule a pull-based computation of that node's contents.
moxie assumes that the program will enter from the "top" of the tree each time. I think that lower level re-entry may be interesting, but the implementation details for moxie would be quite challenging and may not be feasible without language extensions.
My suspicion is that Rust may be fast enough along with the right memoization strategies to never worry about the time spent getting from the root of the tree to nodes with changes. We'll see!
And this brings us to one of the fundamental problems in any push-based incremental approach: it becomes necessary to identify nodes in the output tree, so that it's possible to push content to them.
This is important! In Raph's model, moxie is push-based and moxie-dom and moxie-native incrementally map those push-shaped declarations onto pull-based data structures.6
That said, it's completely feasible to treat it completely as a "tracing" system in Raph's terms, which is what I intend to do with ImGui bindings. moxie would still provide stateful components and memoized reuse of expensive computations, but wouldn't actually retain any tree structure.
Regarding the concrete strategy for identity, moxie's a little bit weird according to Raph's breakdown.
...common approach is some form of key path,...at heart a sequence of directions from the root to the identified node.
Semantically, this is what a topo::Id encodes, where the nodes are function activation records. In
the near future I expect it to be a more literal encoding of this.
...a common choice for other path elements is unique call site identifiers.
Each topo::Id is created at a callsite, so the "node" identifiers in moxie's model are partly made
from callsite identifiers.
Using object references is possible in Rust but...nail down the fact that the tree is stored in a data structure at that
moxie-dom and moxie-native rely on topo::Ids to map from memoization storage to object references
stored between frames. But that doesn't rule out...
...unique identifiers of some kind (usually just integers). This is the basic approach of ECS and also druid before the muggle branch.
...which would also work with memoization storage, I think.
In both Jetpack Compose and imgui, you have a succession of stages which are basically "push" and end up emitting events to a context on the output. These compose well. ... This pattern works especially well for expand-type transformations, as the transformation logic is especially intuitive -- it's just function calls. It's also really clean when the transformation is stateless, otherwise you have the question of how the transformer gets access to state.
Aside: one interesting way to think about moxie is the constrained ability to add memoization and statefulness to computation written to be stateless and pure. Another interesting way to think about moxie is that it allows for imperative code with the "concision of purity."
For one, you do put startGroup and endGroup calls in (these are mostly magically inserted by a compiler plugin, doing source transformation of the original logic). These help the Composer keep track of the key path at all times, which, recall, is an identifier to a specific position in the tree.
And the Composer internally maps that to a slot, which can be used to store state as needed. So basically, even though there's not a tree data structure in memory, when you're in the middle of a transformation stage, you can get access to state for your node as if the tree was materialized.
moxie plays a similar trick with its memoization storage being "lensed" by the current instruction
pointer, as it were. Memoized value storage is indexed by the topo::Id at the callsite where
the value is to be materialized. That new Id comes from the current Id (that of the calling
context, or the "parent" in our abstract tree), the callsite of the new Id (analogous to
startGroup), and some runtime data which moxie calls the "slot." As I mentioned before, that's
typically populated with the number of times the new callsite has been invoked within the current
(parent) Id, allowing for the default behavior in loops to make intuitive sense.
I highly recommend Leland Richardson's Compose From First Principles, as it goes into a fair amount of detail about general tree transformations, and the concept of "positional memoization" as a way to (in the lingo of this blog post) access state of intermediate tree stages in a transformation pipeline.
I also highly recommend Leland's post! In Compose's worldview, moxie might be said to implement "topologically-nested memoization." Ow, that hurts my mouth. Leland and I have talked a few times about how to think about the style of repeatable, declarative functions that moxie and Compose add to their respective languages,7 and it's always been a blast. I look forward to seeing a lot more from that team, especially as they're able to iterate in the open on runtime and language-level features.
There have been a number of attempts to adapt React-style patterns to Rust. Probably the most interesting is moxie.
(moxie) builds key paths to identify nodes in the output tree, and emits the output tree as a trace. Like Imgui, Jetpack Compose, and makepad, it mostly uses function calls to represent the application logic. I look forward to seeing how it progresses.
<3 !!!
To be slightly more precise about my goals re: React, my main goal is to identify the technology needed for the analogous ecosystem niche for Rust. Well, that, and I quite like the Hooks API. I have described moxie a few times as "what if a React in Rust but built out of context and hooks?"
There is some fun nuance here with how moxie actually fits into the broader technical picture Raph paints, but I won't duplicate that here as thats a...lot of what I've already written.
If you're designing one of these systems for scripting, the cross-language boundary is always going to be one of the most important.
I heartily agree, especially having originally started this project thinking about providing a runtime for JavaScript (story for another time, literally). That's actually a significant influence on the ImGui flavor of moxie-dom. Calling functions with a context pointer is IMO much simpler to do across an FFI boundary than to navigate shared ownership of nodes with a managed environment.
Obviously most JS reactive frameworks take DOM as a given, and are organized around it. They also tend to gloss over the implicit state in DOM nodes and downstream, pretending that the only state management concerns are in the transformations from app state up to the DOM.
Agreed! I'm particularly interested to see how moxie-native continues to develop, and whether bets on non-hierarchical memoization pay off in later pipeline phases. This is an area where I see React Native as having struggled quite a bit and I think that Rustic solutions need a higher bar.
Acknowledgementsahoy
cmr, Tiffany, Lucien, Brandon, Nathan and Sunjay all gave their time and attention to review this post and provide invaluable feedback. Thank you!
Q&Aahoy
I've been tinkering with a static-site-friendly comments setup but don't yet have it working. In the meantime, please email me your comments and questions and I'll post them here!
Some thoughts emailed by [Raph]:
I think that most diffing strategies in JS-land compare virtual DOM trees against one another, rather than comparing directly with the DOM. I could be wrong. A good thing to look closely at if someone were to write more summary content!
Oh, absolutely, and I'm sure that's just one of many things that wasn't clear from my blog post. The fundamental model of React (as I understand it) is that building a vdom and then deep-diffing it against the previous version is relatively cheap compared with any actual DOM update. This is, I believe, partly true - it's certainly the case that it's more efficient than any naive approach which does more DOM manip than necessary, but shaky in other contexts. I think in "native GUI land", the DOM is super-expensive, and imgui style approaches (makepad included) give you a very nice performance baseline to quantify this.
So the deeper part is, how do you avoid generating a vdom subtree when it's the same as the previous frame? I think this is often presented in React circles as an optimization trick, as a beginning developer can often get away with not bothering. But, in the general framework, (a) you need access to previous-frame state (which hooks, JC slots, and moxie all do), and (b) you need logic in your app now to compute whether the subtree indeed needs changing (dependency tracking) and tell the next pipeline stage to use the retained subtree.
I think the dependency tracking is one of the hardest parts. It's possible to do it by hand, but that's verbose and error-prone ("make"). Other viable strategies include static analysis of the program source (svelte, JC), but there are many more.
moxie assumes that the program will enter from the "top" of the tree each time. I think that lower level re-entry may be interesting, but the implementation details for moxie would be quite challenging and may not be feasible without language extensions.
I am increasingly convinced this is the right approach, as long as both tree traversal and skipping of subtrees are fast. I think trying not to touch the path from the root to the hot node is a false economy, as you'll often need to do that anyway to propagate invalidations, relayout, etc.
Regarding the concrete strategy for identity, moxie's a little bit weird according to Raph's breakdown.
Not sure why you say this; seems like a pretty standard key path system to me. Most of them use some kind of callsite tracking plus an integer index for collections.
(Note to self: figure out a better way to format replies-to-replies-to-replies...)
Agree without comment on the first and second sections here, and will clarify what I meant by "a
little bit weird according to Raph's breakdown." topo::Ids are indeed "key paths." I think they're
interesting because they are used to mediate storage for other node identities (object references,
ECS IDs, etc.). Re-reading here, I think it may be more accurate to say that Ids are used only to
bridge the invocation syntax to a stored node of some kind, and that node can be identified with
any of the strategies listed. Maybe that's to say that moxie isn't "weird" in this model, it's
attempting to be versatile when integrating with other systems?
Thanks for the reply, good stuff!
Notesahoy
moxie-dom isn't very mature, by the way.
That is, until the source URL changes and I forget to update it.
NB: in addition to keeping the expense of changes proportional to the type of change needed, we also need to have minimal fixed costs imposed by declarative style when resolving UI state.
moxie-native progressively does several tree-to-tree transformations, all of which but the final GPU pass are incremental, and none of which are push-based.
moxie-dom defaults to a push-based API for ease of use with collections and other control flow, but under the hood manipulates a concrete DOM tree to which it exposes "raw" access for the adventurous.
It's important to note that while moxie-dom gains convenience from a push-based API, it loses the
ability to statically verify the correctness of parent/child relationships the way that moxie-native
can by virtue of expressing application logic with a pull-based API. I think there may be solutions
at the language level for this, mainly by offering static checking for #[illicit::from_env(...)]
or a similar feature. Since that's very far away, I consider the two approaches to be exploring
really valuable tradeoff/design points for "declarative UI in Rust." Do we actually find ourselves
significantly more productive with easy control flow for UI elements? How often in practice do
errors occur from having the checks at runtime?
It's also worth noting that as far as "react-alike" systems go, the use of concrete return values from functions is the undisputed "known entity" and projects like Compose and moxie-dom are outliers here.
I have my own suspicions about the "sociotechnical" challenges of producing correct and efficient (enough) software over time with hetergeneous teams of imperfect humans. Interesting parallel: carefully managing the size of incremental changes is a significant component of many successful software engineering practices as well.
I suspect there's also an argument that any software which interactively mediates human activity will eventually find its success bounded by its latency properties. Perhaps this implies there's an argument that meatbag-adjacent technologies should prioritize latency instrumentation and analysis? This has certainly been true of human-facing usage of request/response systems like HTTP services. I think there are some very interesting things moxie can do regarding latency, especially in conjunction with the tracing and tracing-timing crates.
In later phases, moxie-native takes the returned tree, performs incremental layout, and linearizes the tree into a list of display commands with WebRender before sending them to the GPU.
How to think about them except not as pure functional programming constructs ;).